목차
1. LLVM IR 악성코드 탐지 모델 제안
2. 핵심 아이디어
3. 방법
4. 결과
5. 결론
1. LLVM IR 악성코드 탐지 모델 제안
최근 IT 기술이 고도화됨에 따라 악성코드 제작자들은 난독화, 패킹 등 다양한 기법을 활용하여 기존의 시그니처 및 패턴 기반 정적 분석을 우회하고 있습니다. 이에 난독화나 패킹 여부와 관계없이 중간언어 형태로 코드를 표현해주는 LLVM IR 로 악성코드 탐지 모델을 제안합니다.
다음은 간단한 사전 지식입니다.
LLVM란
어셈블리와 유사한 낮은 수준의 프로그래밍 언어인 IR 코드를 생성해주는 컴파일러입니다.
다음 사진은 LLVM 컴파일 기반입니다.
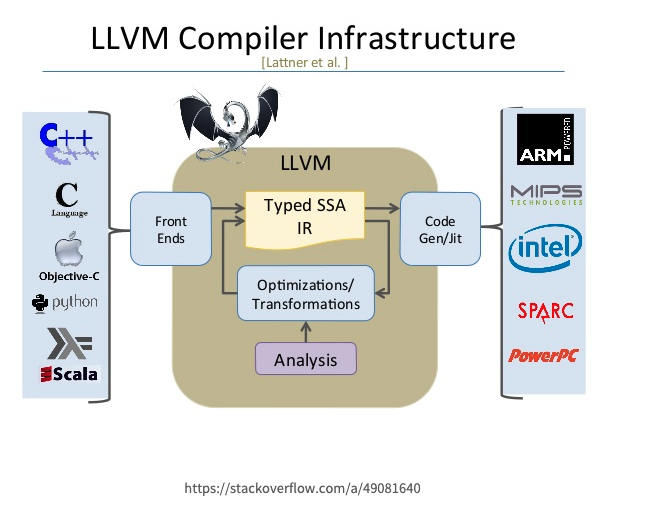
IR 코드는 다음 사진과 같습니다.
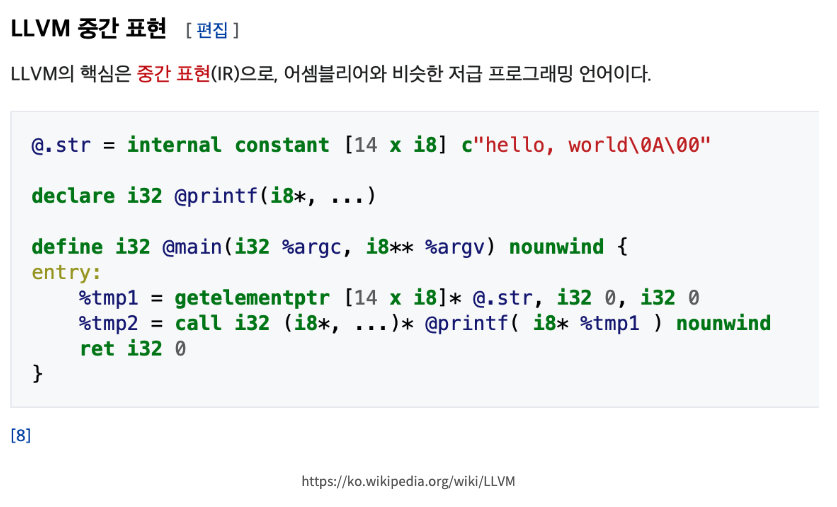
이러한 LLVM IR을 활용한 이미지 기반의 CNN 모델을 제안한 것입니다.
2. 핵심 아이디어
핵심 아이디어는 특정 바이너리 파일을 LLVM IR로 변환한 뒤, 이를 다시 이미지로 변환해서 CNN모델에 적합한 형태로 바꿔주고 이를 학습시키는 것입니다. LLVM IR은 아키텍처에 종속되지 않은 중간 언어로, 난독화나 패킹이 적용되어도 코드의 패턴을 일관되게 분석할 수 있다는 장점으로 이를 이용해 악성코드 탐지를 한다는 것입니다.
다음 사진은 탐지 모델 일련의 과정입니다.
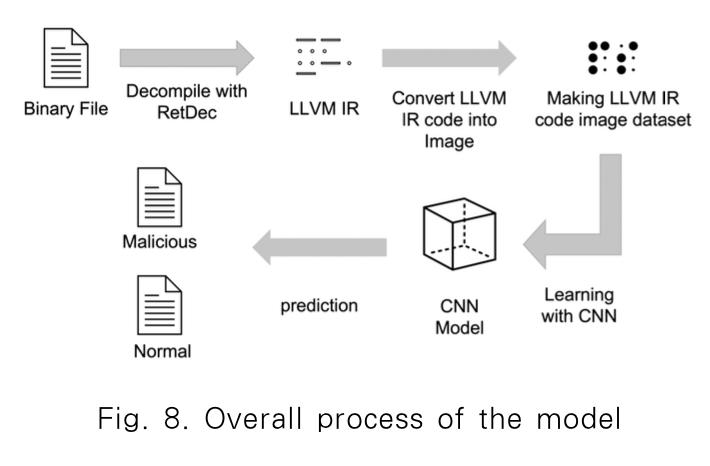
3. 방법
먼저 LLVM IR 코드를 얻기 위해서 리프팅 방식을 사용합니다.
리프팅이란
이미 컴파일된 바이너리 파일을 역으로 컴파일하여 IR 코드 생성되는 부분으로 다시 올라가는 방법입니다.
RetDec 디컴파일러를 사용하여 바이너리 파일을 LLVM IR로 리프팅합니다.
이후 추출된 ".ll" 파일을 LLVM IR을 이미지로 변환하는데 numpy 리스트 형식으로 불러와서 unit8 형식으로 128x128 픽셀 크기의 배열을 생성하고 회색조 변환 기법 전처리를 진행합니다. 이후 이미지를 어두운색과 밝은색으로 이진적 구분하여 CNN 모델을 향상시킵니다.
CNN 모델로는 전이학습이 가능한 텐서플로의 케라스에 있는 ResNet50V2를 사용하고, Adam Optimizer를 활용해 학습을 진행하였습니다.
다음 사진은ResNet50V2를 사용한 모델과 CNN 소스코드입니다.

모델의 코드 구현으로는
CNN을 전이학습 모델로 설정하고 input shape는 데이터셋 이미지 사이즈인 128로 지정하고, Optimizer는 adam으로 지정하였습니다. 그리고 adam으로 지정한 이유는 구현이 간단하고 그 안의 연산이 타 optimizer에 비해 효율적이기에 사용하였다고 합니다. 이후 batch size는 4, epochs는 10, verbose는 1로 지정하여 학습을 진행하였습니다.
4. 결과
이 모델은 악성코드 1,920개와 정상 파일 1,920개로 구성된 데이터셋에서 최대 64%, 평균63.4%의 탐지 성능을 보였습니다. 다른 오픈소스 탐지 모델인 CyberMachine, DeepMalwareDetector와 비교했을 때 비교적 정상적인 탐지가 가능한 모델이라고 평가할 수 있습니다.
5. 결론
본 모델의 알고리즘은 악성코드 탐지 한계가 존재합니다. 악성코드가 시스템 메모리(RAM)에서 바로 실행되어 별도의 실행 파일을 남기지 않는 파일리스, 위조 데이터를 만들어서 기계학습 모델을 공격하는 적대적 공격의 단점이 존재합니다.
향후 지속적인 연구를 통해 패킹된 파일의 특성에 맞는 feature vector와 탐지 기법 추가 적 용을 통해 탐지 성능을 높이는 시스템 구축이 가능할 것이라고 기대 효과를 언급하였습니다.
논문을 읽고 난 후
악성코드를 탐지하는 방식이 기존 연구들과 차별화가 되어 굉장히 신선했고 재미있게 논문을 읽었습니다. 악성코드의 탐지율이 오로지 높은 것만이 좋을 수도 있지만 다양한 관점에서 문제를 바라보는 것이 더 중요하다라고 생각하게 되었습니다. 그렇기 때문에 후속 연구를 통해 제안된 모델이 더욱 개선되고 실용화 되면 정말 좋을것 같다고 생각했습니다.
인용, 출처 :
박경빈, 윤요섭, 또 올 가, 임강빈. (2024). LLVM IR 대상 악성코드 탐지를 위한 이미지 기반 머신러닝 모델. 정보보호학회논문지, 34(1), 31-40.